J'ai eu l'occasion de le dire récemment à mes étudiants de Metz : l'apprentissage du code doit avant tout produire des effets. Inutile d'aligner de belles fonctions juste pour la beauté du geste ou pour se distinguer de certains confrères moins à l'aise en technique.
Comme ce n'était pas qu'un voeu pieux et qu'il faut bien justifier l'autocollant Python collé sur mon ordi portable cette semaine, je me suis penché sur la rédaction de deux scripts codés dans ce langage.

En résumé :
- un premier script qui va créer un fichier csv en réagençant des informations piochées sur la page Wikipedia consacrée aux monuments historiques de Strasbourg. Ce fichier clé en main pourra être lu dans QGis, avec localisation et principales infos de chaque monument.
- un second fichier py qui va automatiser l'extraction d'infos sur ces monuments historiques pour plusieurs villes du Grand-Est
Pourquoi Python ?
J'avais déjà un peu répondu à cette question dans un précédent billet, ceci dit dans le domaine du webscraping la question peut être légitime, notamment quand on connaît des fonctions GDrive comme importHTLM.
Si l'on reprend la page Wikipedia dédiée aux monuments historiques de Strasbourg, il nous suffirait de créer un nouveau tableur Google et d'insérer cette formule dans la première cellule :
=importHTML("https://fr.wikipedia.org/wiki/Liste_des_monuments_historiques_de_Strasbourg","table",1)
Cette petite ligne aura pour effet d'importer directement le premier tableau de la page Wikipedia, comme sur la capture :
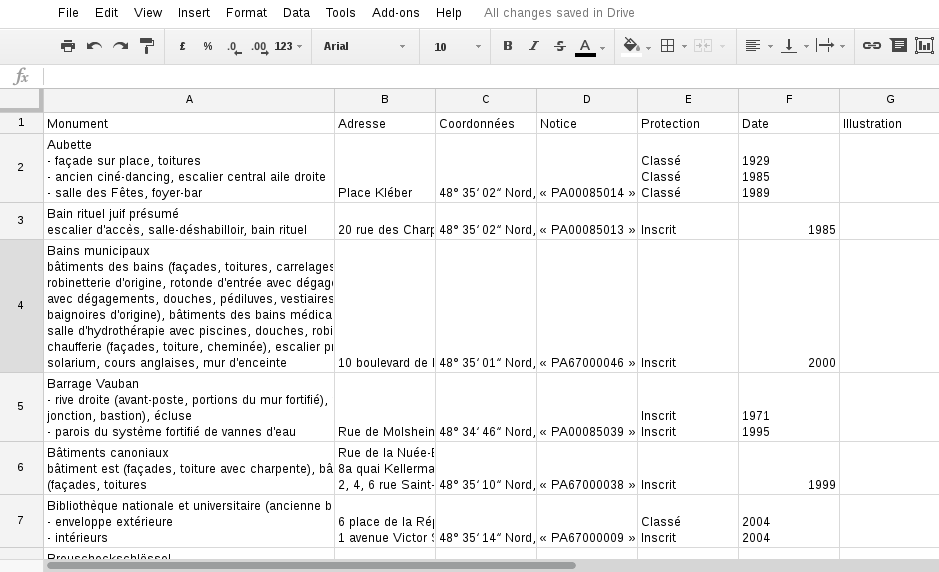
A première vue, cela semble bel et bon, mais à y regarder de plus près il y a quand même quelques écueils, par exemple :
- la première colonne qui inclut non seulement le nom du monument, mais souvent des infos contextuelles pas forcément utiles
- la colonne "Coordonnées" qui est inexploitable en l'état. Pour que notre fichier csv contienne des informations géographiques susceptibles d'être lues par un logiciel comme QGis ou une librairie comme D3, il faut séparer la latitude et la longitude de chaque monument. La confiture avec des degrés, ça marchera pas !
- la colonne "Notice" qui liste la source pour chaque monument, avec un lien pointant sur le site culture.gouv.fr. Sauf que là l'information qui nous intéresserait (le lien) n'a pas été importée !
C'est d'autant plus frustrant qu'en regardant le code source de la page, certaines données meta ont beaucoup plus d'intérêt. On retiendra :
- le "data-sort-value" contenant uniquement le nom du monument, sans aucune autre information contextuelle
- les classes "p-latitude" et "p-longitude" qui contiennent les latitudes et longitudes précises de chaque monument. Tiens tiens !
- l'attribut "href" des liens pointant vers chaque source
Autre point important : cette structure est strictement la même que pour la page consacrée aux monuments historiques de Reims ou ceux de Metz. Vous me voyez venir avec mes gros sabots :-) ?
Donc, à la question : est-ce qu'un script Python peut extraire des données à la carte sur différentes page Wikipedia structurées de la même façon ?, je répondrai sans ambage oui, et c'est parti pour la démonstration !
Les modules utilisés pour nos scripts
Je ne vais pas trop m'attarder sur les caractéristiques de chaque module utilisé, même si des petites présentations s'imposent. Les nominés sont donc :
- urllib, qui va nous permettre d'ouvrir des URL
- BeautifulSoup, qui va extraire nos différentes infos
- re, qui va nous permettre d'inclure des expressions régulières. Nous aurons l'occasion d'y revenir !
- et enfin le module csv, qui va comme son nom l'indique nous permettre de créer et compléter notre fichier csv
Avant de passer à la suite, je précise que j'utilise ces différents modules sur un ordi tournant sous Debian, donc pas sur la version la plus récente de Python. Mais la logique est strictement la même !
Premiers tests
On va commencer léger en testant quelques commandes pour voir si elles nous retournent bien les informations attendues. On commence par les incontournables importations de modules :
import urllib
import re
from bs4 import BeautifulSoup
import csv
Une fois ceci fait, on paramètre les variables de départ. Ces dernières vont inclure dans l'ordre l'URL, l'ouverture de cette URL et la transformation de la page web en élément BeautifulSoup :
depart ="https://fr.wikipedia.org/wiki/Liste_des_monuments_historiques_de_Strasbourg"
url = urllib.urlopen(depart).read()
soupe = BeautifulSoup(url)
On pourrait d'ores et déjà faire un print(soupe) pour voir ce que renvoie cet objet (grosso modo un équivalent de ce qui s'affiche dans le code source de la page), mais on va plutôt commencer par sélectionner le tableau qui nous intéresse comme suit :
tableau = soupe.find("table", {"class":"wikitable sortable"})
Notre variable tableau renvoie désormais au premier élément "table" de classe "wikitable sortable" rencontré dans la page. Les sélections avec BeautifulSoup se font toujours de la sorte : élément.find("nom de balise", {"nom de l'attribut" : "valeur de l'attribut"}).
C'est pas mal, mais on peut encore affiner notre sélection avec toutes les lignes (balises "tr") de notre tableau :
lignes = tableau.findAll("tr")
Vous remarquerez qu'on a utilisé ici la méthode findAll(), et non find(). C'est normal, puisque toutes les lignes de l'élément tableau nous intéresse !
On pourrait être tenté d'afficher chaque ligne de cette nouvelle variable comme suit :
for ligne in lignes:
print(ligne)
Le terminal renverrait alors les lignes les unes à la suite des autres, sous cette forme :
<tr id="Maison">
<td data-sort-value="Maison"><a href="/wiki/Maison_au_21_rue_Sainte-Barbe_%C3%A0_Strasbourg" title="Maison au 21 rue Sainte-Barbe à Strasbourg">Maison</a><br/>
<small>jambages de porte</small></td>
<td data-sort-value="Sainte-Barbe Rue 021">21 rue Sainte-Barbe</td>
<td style="text-align:center; width:9em;"><span class="plainlinks nourlexpansion" title="Cartes, vues aériennes, etc."><a class="external text" href="http://tools.wmflabs.org/geohack/geohack.php?language=fr&pagename=Liste_des_monuments_historiques_de_Strasbourg&params=48.581346_N_7.745742_E_type:landmark_region:FR&title=Maison+%2821+rue+Sainte-Barbe+-+Strasbourg%29"><span class="h-card"><data class="p-name" value="Maison (21 rue Sainte-Barbe - Strasbourg)"></data><span class="h-geo geo-dms"><data class="p-latitude" value="48.581346">48° 34′ 53″ Nord</data>, <data class="p-longitude" value="7.745742">7° 44′ 45″ Est</data></span></span></a></span></td>
<td><span class="ouvrage"><a class="external text" href="http://www.culture.gouv.fr/public/mistral/merimee_fr?ACTION=CHERCHER&FIELD_1=REF&VALUE_1=PA00085157" rel="nofollow">« <cite style="font-style: normal">PA00085157</cite> »</a></span></td>
<td>Inscrit</td>
<td>1929</td>
<td>
<div class="center">
<div class="floatnone"><a class="image" href="/wiki/Fichier:Maison_au_21_rue_Sainte_Barbe_%C3%A0_Strasbourg_(3).jpg"><img alt="Maisonjambages de porte" data-file-height="4000" data-file-width="3000" height="120" src="//upload.wikimedia.org/wikipedia/commons/thumb/6/6e/Maison_au_21_rue_Sainte_Barbe_%C3%A0_Strasbourg_%283%29.jpg/90px-Maison_au_21_rue_Sainte_Barbe_%C3%A0_Strasbourg_%283%29.jpg" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/6/6e/Maison_au_21_rue_Sainte_Barbe_%C3%A0_Strasbourg_%283%29.jpg/135px-Maison_au_21_rue_Sainte_Barbe_%C3%A0_Strasbourg_%283%29.jpg 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/6/6e/Maison_au_21_rue_Sainte_Barbe_%C3%A0_Strasbourg_%283%29.jpg/180px-Maison_au_21_rue_Sainte_Barbe_%C3%A0_Strasbourg_%283%29.jpg 2x" width="90"/></a></div>
</div>
</td>
</tr>
L'objectif est alors d'extraire à chaque passage dans notre boucle for les fameux éléments qui nous intéressent. On va procéder à :
- une sélection globale des cellules de chaque ligne (puisqu'aucune classe ne distingue les monuments de leurs adresses)
- une sélection de la longitude et la latitude grâce aux classes p-longitude et p-latitude
- une sélection des liens pointant vers le site culture.gouv.fr, et ce grâce à l'expression régulière "^http://www.culture.gouv", qui signifie qu'on ne retient que les chaînes de caractères commençant par "http://www.culture.gouv"
Adelante, donc !
for ligne in lignes:
monuments = ligne.findAll("td")
longitude = ligne.find("data", {"class":"p-longitude"})
latitude = ligne.find("data", {"class":"p-latitude"})
source = ligne.findAll("a", {"href":re.compile("^http://www.culture.gouv")})
On pourrait par curiosité afficher la latitude et la longitude à chaque passage dans la boucle :
for ligne in lignes:
monuments = ligne.findAll("td")
longitude = ligne.find("data", {"class":"p-longitude"})
print(longitude)
latitude = ligne.find("data", {"class":"p-latitude"})
print(latitude)
source = ligne.findAll("a", {"href":re.compile("^http://www.culture.gouv")})
Cela renverrait dans le terminal des doublettes comme :
<data class="p-longitude" value="7.74956">7° 44′ 58″ Est</data>
<data class="p-latitude" value="48.57703">48° 34′ 37″ Nord</data>
Or, ce qui nous intéresse c'est juste la valeur de l'attribut "value". Il faut donc affiner à nouveau les sélections, en vérifiant au préalable l'existence des variables, monuments, longitude, latitude et source. Concrètement, cela va donner :
for ligne in lignes:
monuments = ligne.findAll("td")
longitude = ligne.find("data", {"class":"p-longitude"})
latitude = ligne.find("data", {"class":"p-latitude"})
source = ligne.findAll("a", {"href":re.compile("^http://www.culture.gouv")})
if monuments and longitude and latitude and source:
monument = monuments[0].get("data-sort-value")
adresse = monuments[1].get_text()
longitude_valeur = longitude.get('value')
latitude_valeur = latitude.get('value')
lien = source[0].get('href')
print(monument, adresse, longitude_valeur, latitude_valeur, lien)
Il faut se rappeler que "lignes" contient toutes les cellules de chaque ligne du tableau, et toutes les cellules ne contiennent pas la même chose. C'est pour ça qu'on teste l'existence de nos variables avec un if (sinon il y a tout de suite une erreur).
Si vous ne vous êtes pas loupés, le terminal devrait afficher les résultats comme suit :
('Villa Stempel', u'4 rue Erckmann Chatrian', '7.764953', '48.588848', 'http://www.culture.gouv.fr/public/mistral/merimee_fr?ACTION=CHERCHER&FIELD_1=REF&VALUE_1=PA67000079')
Yipikaye ! On a les bonnes infos qui s'affichent, l'esentiel rien que l'essentiel.
Il ne reste plus qu'à les enregistrer dans un csv !
La mise à jour du csv dans la boucle for
L'adaptation de notre précédent script avec la mise à jour d'un csv n'a rien de très difficile. Pour le dire vite, il suffit d'ajouter avant la boucle une variable, par exemple :
ficsv = open('monuments_histo_strabourg.csv','w+')
On va créer à partir de rien un fichier nommé monuments_histo_strasbourg.csv, avec droit d'écriture pour pouvoir le mettre à jour.
Il va juste falloir inclure une étape d'écriture des noms de colonne et une fermeture de fichier une fois tous les monuments renseignés. Et entre ces deux étapes on va devoir évidemment mettre à jour le csv à chaque passage dans la boucle for.
Concrètement, cela va donner :
try:
majcsv = csv.writer(ficsv)
majcsv.writerow(('Monument','Adresse','Longitude','Latitude','Source'))
for ligne in lignes:
monuments = ligne.findAll("td")
longitude = ligne.find("data", {"class":"p-longitude"})
latitude = ligne.find("data", {"class":"p-latitude"})
source = ligne.findAll("a", {"href":re.compile("^http://www.culture.gouv")})
if monuments and longitude and latitude and source:
monument = monuments[0].get("data-sort-value").encode('utf-8')
adresse = monuments[1].get_text().encode('utf-8')
longitude_valeur = longitude.get('value')
latitude_valeur = latitude.get('value')
lien = source[0].get('href')
majcsv.writerow((monument, adresse, longitude_valeur, latitude_valeur, lien))
finally:
ficsv.close()
Si on exécute notre script, le fichier csv créé dans le même dossier devrait se présenter sous la forme :
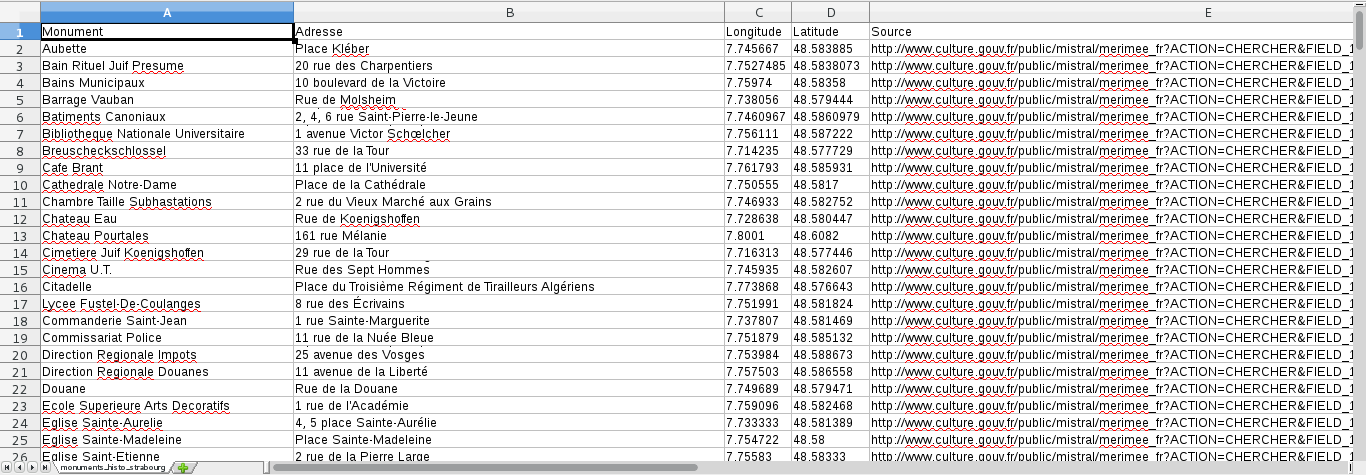
On est vraiment pas mal à ce stade, mais pourquoi ne pas encore pimenter un peu la chose en automatisant ce script sur plusieurs pages Wikipedia ?
Scraper les monuments des principales villes du Grand-Est
La structure de Wikipedia va grandement nous aider pour l'extraction sur plusieurs pages. En gros, chaque liste de monuments historiques commence de la même façon, on peut donc définir deux variables telles que :
depart ="https://fr.wikipedia.org/wiki/Liste_des_monuments_historiques_d"
villes = ["e_Reims", "e_Chaumont", "e_Charleville-Mézières", "e_Troyes", "e_Verdun", "e_Bar-le-Duc", "'Épinal", "e_Nancy", "e_Metz", "e_Colmar", "e_Sélestat", "e_Mulhouse", "e_Strasbourg"]
De cette façon, on peut obtenir les listes de chaque commune en additionnant depart avec une des valeurs de villes. En ajoutant une boucle for parcourant ce tableau, on peut dès lors programmer notre scraper comme ceci :
ficsv = open('monuments_histo_ge.csv','w+')
try:
majcsv = csv.writer(ficsv)
majcsv.writerow(('Monument','Adresse','Longitude','Latitude','Source'))
for ville in villes:
url_ville = depart+ville # une simple addition de chaînes de cara' nous donne nos URL complètes
url = urllib.urlopen(url_ville).read() # et on ouvre chacu d'entre elles
print("Lien : "+url_ville)
soupe = BeautifulSoup(url)
tableau = soupe.find("table", {"class":"wikitable sortable"}) # on chope le premier tableau de classe "wikitable sortable"
lignes = tableau.findAll("tr") # puis toutes ses lignes
for ligne in lignes:
monuments = ligne.findAll("td") # on fait les premières sélections
longitude = ligne.find("data", {"class":"p-longitude"})
latitude = ligne.find("data", {"class":"p-latitude"})
source = ligne.findAll("a", {"href":re.compile("^http://www.culture.gouv")})
if monuments and longitude and latitude and source:
monument = monuments[0].get("data-sort-value") # si les sélections existent, on balance
if monument: # là j'ai dû rajouter un test, ai pas bien compris pourquoi
monument = monument.encode('utf-8') # on est obligé d'encoder en UTF-8, sinon ça plante
adresse = monuments[1].get_text().encode('utf-8')
longitude_valeur = longitude.get('value')
latitude_valeur = latitude.get('value')
lien = source[0].get('href')
print(monument, adresse, longitude_valeur, latitude_valeur, source)
majcsv.writerow((monument, adresse, longitude_valeur, latitude_valeur, lien))
finally:
ficsv.close()
J'en profite pour signaler que pour éviter tout pépin avec les accents et autres dans la variable villes, on est obligé de commencer notre script avec les commentaires suivants :
1 2 | #!/usr/bin/python
# -*- coding: utf-8 -*-
|
Une fois exécuté, ce script ordonnera en une dizaine de secondes les quelques 1 111 monuments répartis sur ces 13 villes. Le CSV en question sera parfaitement digéré par QGis comme vous pourrez l'apprécier sur cette capture :
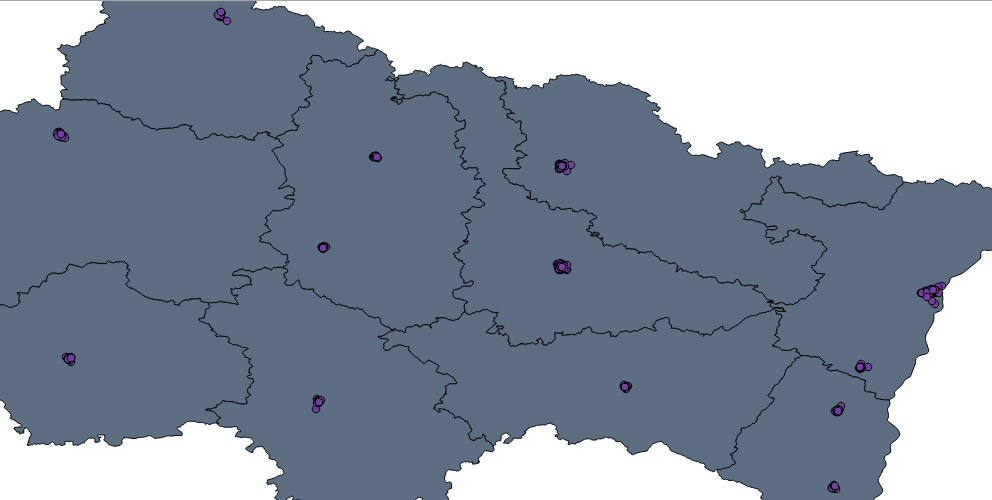
Bref, un fichier propre et exploitable grâce à une quarantaine de lignes de code ! Qui dit mieux :-) ?
Point Github
J'ai publié ces deux scripts sur mon compte Github. Pour toute question et/ou remarque, mon mail : raphipons[at]gmail.com
Autre chose : pensez à donner un peu de pognon à Wikipedia, comme vous pourrez le constater c'est une mine d'info extrêmement profitable !