Ce tuto constitue un exercice un peu particulier que l'on pourrait résumer ainsi : un data-défi réalisé uniquement en Python, sans jamais avoir recours au moindre logiciel. Il consiste en :
- la création d'une base de données de référence
- l'import d'une BDD géographique
- le bon formatage de cette dernière
- sa mise à jour à partir d'infos de la première BDD
L'idée a été soufflée par l'excellent Joël Matriche, qui voulait marquer la Journée internationale des droits des femmes avec une carto des rues de Liège. Pour le dire vite, il s'agissait de comparer les rues rendant hommage à des figures féminines et masculines.
Et à la question "peut-on traiter ces données et en faire un fichier géographique propre en utilisant que du Python ?", je répondrai sans ambage "oui, dès lors que l'on tolère l'une ou l'autre limite" !
C'est parti pour la démo avec Liège, qui peut s'adapter à n'importe quelle autre ville !
Import des bibliothèques
Une fois n'est pas coutume, on entame les festivités en important quelques bibliothèques. Le clou du spectacle est la récente OSMnx, qui permet de télécharger, d'afficher et/ou de réenregistrer des données d'OpenStreetMap.
Je vous invite vivement à consulter le lien précédent, notamment pour avoir la liste des modules nécessaires à son bon fonctionnement.
Une fois que tout est installé, on peut se lancer :
%matplotlib inline
import csv, requests, pandas as pd, osmnx as ox, matplotlib.pyplot as plt, fiona
from descartes import PolygonPatch
from shapely.geometry import Polygon, MultiPolygon, shape
ox.config(log_console=True, use_cache=True)
Une base de données débordant de prénoms
Après tous ces imports, on va commencer par créer un CSV de référence, qui contiendra une base de données remplie de prénoms rattachés à un ou deux genres.
Cela nous servira notamment à faire la correspondance avec les données téléchargées sur OSM.
On peut directement ce fichier avec Python depuis cette adresse en utilisant notamment requests :
url = "https://raw.githubusercontent.com/armgilles/Street-Gender-CUB/master/data/Gender1.csv"
page = requests.get(url).text
fichier = open('bdd_noms.csv', 'w')
fichier.write(page)
fichier.close()
L'esprit léger, on peut observer un aperçu de cette base de 40 000 prénoms.
J'insiste quand même sur l'encodage des chaînes de caractères : de l'UTF-8 pour l'ensemble des bases de données, rien d'autre.
Si on ne le précise pas, on risque d'avoir de très mauvaises surprises en tentant des rapprochements entre chaînes de caractères encodées différemment.
Maintneant que c'est dit, on va se servir de pandas pour transformer le fichier csv en DataFrame :
base_reference = pd.read_csv("bdd_noms.csv", sep=',', encoding='utf-8') # ce encoding = 'utf-8', on n'a pas fini d'en bouffer
base_reference.head() # head() sert juste à afficher les cinq premières valeurs de la DF
| Genre | Genre_detail | Genre_main | Prenom | |
|---|---|---|---|---|
| 0 | ?F | Surement Femme | Femme | aaf |
| 1 | F | Femme | Femme | aafke |
| 2 | F | Femme | Femme | aafkea |
| 3 | M | Homme | Homme | aafko |
| 4 | M | Homme | Homme | aage |
Détail qui a son importance : les prénoms ne commencent pas avec des majuscules. Autant dire qu'il faut remédier à ça avant de se lancer avec les rapprochements.
On peut le faire en deux coups de cuillère à pot avec la commande :
base_reference['Prenom']=base_reference['Prenom'].str.title()
base_reference.head()
| Genre | Genre_detail | Genre_main | Prenom | |
|---|---|---|---|---|
| 0 | ?F | Surement Femme | Femme | Aaf |
| 1 | F | Femme | Femme | Aafke |
| 2 | F | Femme | Femme | Aafkea |
| 3 | M | Homme | Homme | Aafko |
| 4 | M | Homme | Homme | Aage |
Une des particularités pour transformer des données avec pandas est de raisonner en gros volumes plutôt qu'avec des réflexes itératifs type boucle for. J'aurai l'occasion d'y revenir un peu plus tard !
Importer toutes les rues d'une ville avec OSMnx
On peut à présent s'attaquer à la partie géographique de l'exercice. Pour ça, on va faire chauffer le récent module Python nommé OSMnx.
Celui-ci permet notamment de :
- interroger les serveurs d'OpenStreetMap
- importer certains réseaux routiers (piétons, automobiles, cyclistes, rayez les mentions inutiles) => ça nous intéresse !
- analyser lesdits réseaux
- enregistrer ces réseaux dans un format géographique type shp => ça nous intéresse également !
Voici le code associé :
contours_liege = ox.gdf_from_place('Liège, Belgique')
contours_liege = ox.project_gdf(contours_liege)
# les deux lignes précédentes c'est un fond de carte juste pour faire joli, on peut s'en passer
rues_liege = ox.graph_from_place('Liège, Belgique', network_type='walk', retain_all=True)
# c'est là qu'on peut changer de ville et éventuellement considérer un autre réseau de voies => 'walk' retient toutes les rues
rues_liege = ox.project_graph(rues_liege)
# à partir de là, on paramètre le graphe à afficher. Pareil que le fond de carte, on pourrait s'en passer
fig, ax = ox.plot_graph(rues_liege, fig_height=10, show=False, node_size=0, close=False, edge_color='#777777')
for geometry in contours_liege['geometry'].tolist():
if isinstance(geometry, (Polygon, MultiPolygon)):
if isinstance(geometry, Polygon):
geometry = MultiPolygon([geometry])
for polygon in geometry:
patch = PolygonPatch(polygon, fc='#cccccc', ec='k', linewidth=3, alpha=0.1, zorder=-1)
ax.add_patch(patch)
plt.show
<function matplotlib.pyplot.show>
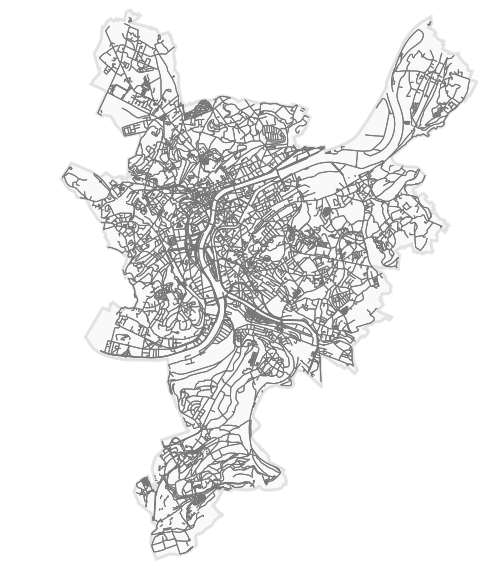
Splendide ! On peut transformer la variable rues_liege en fichier shp simplement en utilisant la commande :
ox.save_graph_shapefile(rues_liege, filename='rues_liege', encoding='utf-8')
Optimisation du fichier géographique
A ce stade, on est plutôt bien parti. On peut jeter un coup d'oeil aux données du fichier géographique (en utilisant geopandas) comme suit :
from geopandas import GeoDataFrame
gdf = GeoDataFrame.from_file('data/rues_liege/edges/edges.shp', encoding = 'utf-8') # surtout ne pas oublier l'UTF-8
gdf = gdf.sort('name') # on trie nos différentes rues par nom pour une meilleure lisibilité
gdf.reset_index(drop=True) # on crée un nouvel index qui suit ce tri
| access | bridge | est_width | from | geometry | highway | key | lanes | length | maxspeed | name | oneway | osmid | ref | service | to | tunnel | width | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | None | None | None | 3706649855 | LINESTRING (683233.9727872496 5615156.43551744... | track | 1 | None | 52.0496325025 | None | Accès privé | False | 366672325 | None | None | 3414186589 | None | 3 |
| 1 | None | None | None | 430937354 | LINESTRING (685791.9166955455 5611212.34820444... | living_street | 0 | None | 28.0658685307 | None | Al'rodje-creu | False | 37053875 | None | None | 1139397183 | None | None |
| 2 | None | None | None | 430937357 | LINESTRING (685881.4479234623 5611292.44178162... | living_street | 0 | None | 133.504534207 | None | Al'rodje-creu | False | 37053875 | None | None | 1139397183 | None | None |
| 3 | None | None | None | 430937354 | LINESTRING (685832.6157903547 5611129.98358485... | living_street | 0 | None | 84.7229366839 | None | Al'rodje-creu | False | 37053874 | None | None | 430937351 | None | None |
| 4 | None | None | None | 1035627020 | LINESTRING (685734.0739504495 5611091.42553181... | ['footway', 'living_street'] | 0 | None | 109.978440168 | None | Al'rodje-creu | False | [98487536, 37053875] | None | None | 430937354 | None | None |
| 13320 | None | None | None | 430276540 | LINESTRING (686760.8462367456 5612389.35792956... | ['track', 'service'] | 0 | None | 41.0865165025 | None | None | False | [36997065, 36997067] | None | alley | 430276538 | None | None |
| 13321 | None | None | None | 1467989989 | LINESTRING (681783.8166806753 5613597.94656746... | footway | 0 | None | 9.22518986926 | None | None | False | 133353876 | None | None | 1467989974 | None | None |
13322 rows × 18 columns
Deux remarques :
- il y a pas mal d'infos qui ne sont pas intéressantes. En fait, on ne peut retenir que la colonne 'name'
- il y a des doublons, beaucoup de rues étant composées de segments distincts. Pas glop, il faudra s'en occuper par la suite !
On va commencer par le plus simple et virer les colonnes pas utiles. Voici la manip :
gdf = gdf.drop(['access','bridge','est_width','from','highway','key','lanes','length','maxspeed','oneway','osmid','ref','service','to','tunnel','width'], axis=1)
gdf.tail()
| geometry | name | |
|---|---|---|
| 13309 | LINESTRING (681855.5877330278 5606787.08796601... | None |
| 13311 | LINESTRING (680394.5838991912 5605834.34821477... | None |
| 13312 | LINESTRING (686883.2818331933 5612508.98135232... | None |
| 13313 | LINESTRING (686760.8462367456 5612389.35792956... | None |
| 13320 | LINESTRING (681783.8166806753 5613597.94656746... | None |
On va enregistrer la GeoDataFrame en shp, quitte à écraser le fichier précédent. Voici les commandes associées :
gdf.crs= "+proj=longlat +ellps=WGS84 +datum=WGS84 +no_defs" # une petite projection Mercator, au cas où
gdf.to_file('data/rues_liege/edges/edges.shp', driver='ESRI Shapefile', encoding = 'utf-8' )
On arrive enfin au gros morceau : la chasse aux doublons. Le problème est le suivant :
- on a plus de 13 300 segments, dont beaucoup ont le même nom
- c'est pas exemple le cas de tous les segments type sentiers de parcs ou mares quelconques, sobrement nommés "None"
L'idéal serait de fusionner les segments qui ont le même nom pour faciliter l'interrogation du fichier avec la BDD du début et aussi par souci pratique.
Si vous programmez une carte qui affiche le nom d'une rue au survol de la souris, il vaut mieux mettre en lumière la rue entière plutôt qu'un seul de ses segments !
Une bonne solution est de partir d'un des exemples décrits par Tom MacWright sur son blog.
L'idée est la suivante :
- on ouvre notre premier fichier géo en tant que variable nommée input
- on définit un schéma qui correspondra à chaque entrée d'un nouveau fichier. Dans notre cas, il y aura un champ géométrie MultiLineString et deux champs propriétés (le nom plus un nouveau champ nommé 'genre')
- on crée un second fichier géo en tant que variable nommée output
Une fois ceci fait, on crée trois variables :
- shapes, une liste qui contiendra tous les segments d'une rue
- doublons, une liste qui contiendra tous les index de segments partageant un même nom
- nindex, qui correspondra au nouvel index collé sur le nouveau segment ( nouveau segment qui correspond à la fusion de ceux qui partagent le même nom)
Et après, on manipule tout ça avec boucles for et conditions comme suit :
from shapely.geometry import mapping, shape
from shapely.ops import cascaded_union
from fiona import collection
with collection("data/rues_liege/edges/edges.shp", "r", encoding='utf-8') as input:
schema = {'geometry': 'MultiLineString', 'properties': [('nom', 'str:80'),('genre', 'str:80')]}
with collection("data/rues_liege/edges/liege_rues_def.shp", "w", "ESRI Shapefile", schema, encoding = 'utf-8') as output:
shapes = []
doublons= []
nindex = 0
for segment in input:
index = int(segment['id'])
if ((index+1) < len(input)): # cette condition permet de comparer les segments deux à deux sans déborder du fichier
doublons.append(index) # on part du principe que les segments ont le même nom, et on implémente donc doublons
segment_depart = input[index]
segment_compare = input[index+1]
nom_depart = segment_depart['properties']['name']
nom_compare = segment_compare['properties']['name']
if (nom_depart != nom_compare): # si jamais les segments comparés n'ont pas le même nom...
nindex+=1 # ...on ajoute une unité à nindex puisqu'on s'apprête à figer un nouveau segment
for doublon in doublons: # on passe en revue tous les index stockés dans doublons
seg = input[doublon]
shapes.append(shape(seg['geometry'])) # et on stocke chaque bout de segment dans shapes
fusion = cascaded_union(shapes) # on fusionne tous les segments de shapes pour avoir un unique tracé
# plus qu'à créer une nouvelle entrée dans le nouvau fichier
output.write({'properties': {'nom': nom_depart, 'genre' : 'indéfini'},'id':nindex,'geometry': mapping(fusion)})
# pour finir, on vide les listes doublons et shapes pour recommencer la manip
doublons = []
shapes = []
else: # ça c'est pour fusionner tous les segments nommés 'None' (et y en a un paquet !)
for doublon in doublons:
seg = input[doublon]
shapes.append(shape(seg['geometry']))
fusion = cascaded_union(shapes)
output.write({'properties': {'nom': 'None', 'genre' : 'indéfini'},'id':nindex,'geometry': mapping(fusion)})
Le code précédent peut sans doute être allégé (on peut à mon avis se passer de la liste doublons), mais cette méthode me paraît très facilement compréhensible et pas spécialement lourde en termes de temps. Après tout en moins de dix secondes c'est plié !
On peut maintenant vérifier que la chasse aux doublons a marché en réutilisant geopandas :
gdef = GeoDataFrame.from_file('data/rues_liege/edges/liege_rues_def.shp', encoding = 'utf-8')
gdef.tail()
| genre | geometry | nom | |
|---|---|---|---|
| 1751 | indéfini | LINESTRING (681947.2206223279 5607301.44684974... | rue du Clairbois |
| 1752 | indéfini | (LINESTRING (683219.6187426309 5615498.0371011... | rue du Préay |
| 1753 | indéfini | LINESTRING (686248.7302026513 5611373.79958617... | sentier des Trois Chemins |
| 1754 | indéfini | (LINESTRING (681803.9748203105 5613762.9612600... | Éscaliers des Capucins |
| 1755 | indéfini | (LINESTRING (681038.9843025684 5604392.0459795... | None |
On est bien passé de 13 321 segment à seulement 1 756. Il est temps maintenant de passer à la dernière étape !
Mise à jour du 'genre' dans le fichier géographique
On va maintenant utiliser notre base de référence du début pour pouvoir établir des correspondances. Toute notre base ? Non, seuls deux attributs nous intéressent : le prénom et le genre associé.
Le format de données idéal pour agencer ça est le dictionnaire. Ce format de données associe un objet à une clé, comme un mot est associé à sa définition dans le dictionnaire !
Dans notre cas, chaque prénom sera associé à un genre. La création de notre dico se fera simplement avec :
dico = base_reference.set_index('Prenom')['Genre'].to_dict()
print (dico['Raphaël'])
print(dico['Rafael'])
print(dico['Dominique'])
print(dico['Édouard'])
M
M
?F
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-15-1de356152dfe> in <module>()
2 print(dico['Rafael'])
3 print(dico['Dominique'])
----> 4 print(dico['Édouard'])
KeyError: 'Édouard'
Donc, on n'a pas de Dominique ni d'Édouard... Qu'à cela ne tienne, on peut ajouter des entrées dans le dictionnaire à l'aise avec la commande :
dico['Dominique'] = '?F'
dico['Édouard'] = 'M'
print(dico['Dominique'])
print(dico['Édouard'])
?F
M
Certaines rues sont liées à des personnalités sans qu'un prénom apparaisse ('la Reine', 'le Prince', 'de Gaulle', etc...)
On peut également facilement mettre à jour le dictionnaire avec des listes d'exceptions et deux boucles for, comme ceci :
exceptions_f = ['de la Princesse', 'de la Reine']
exceptions_m = ['Churchill', 'du Roi', 'de Gaulle']
for exceptf in exceptions_f:
dico[exceptf] = 'F'
for exceptm in exceptions_m:
dico[exceptm] = 'M'
print(dico['de la Princesse'])
print(dico['Churchill'])
F
M
Là, c'est typiquement à vous de paramétrer vous-mêmes vos exceptions en fonction de vos connaissances de la ville.
Bref, tout ça pour dire qu'on peut enfin transformer la colonne 'genre' dans notre GeoDataFrame. Yipikaye !
La méthode la plus simple consiste à éclater chaque entrée de la colonne 'nom' au niveau des espaces et de ne retenir que le deuxième terme (en général le prénom). En langage pandas ça donne :
gdef['genre'] = gdef['nom'].str.split().str[1].map(dico).fillna('indéfini')
print (gdef.head())
genre geometry \
0 indéfini LINESTRING (683233.9727872496 5615156.43551744...
1 ?F (LINESTRING (685881.4479234623 5611292.4417816...
2 indéfini (LINESTRING (680907.7755790278 5617511.5281642...
3 ?M (LINESTRING (685055.2839771766 5609963.5753307...
4 indéfini LINESTRING (679494.3692617267 5616710.90200582...
nom
0 Accès privé
1 Al'rodje-creu
2 Allée Bietîmé
3 Allée Edgard D'Hont
4 Allée Grande Hollande
On a un problème avec Al'rodjge-creu, dans le nom de rue ne fait qu'un terme. Cela pourrait se résoudre en mettant par exemple à jour le dico.
Pour les noms composés comme "de la Princesse", on pourrait utiliser une combinatoire comme celle décrite dans les commentaires de ce post StackOverflow.
Il ne nous reste plus qu'à exporter notre fichier, par exemple en GeoJSON avec la commande :
gdef.to_file('liege_rues_def.json', driver='GeoJSON', encoding = 'utf-8' )
Et voilà ! Cette recette balbutiante est sans doute perfectible mais a le mérite d'être reproductible avec toutes les villes imaginables.
Pour toute remarque, je rappelle mon mail : raphipons[at]gmail.com